HashMap
实现原理
HashMap用于存储键值对,内部为散列表(一个数组),每个数组槽位是一个链表或红黑树,即类似桶排序的结构。
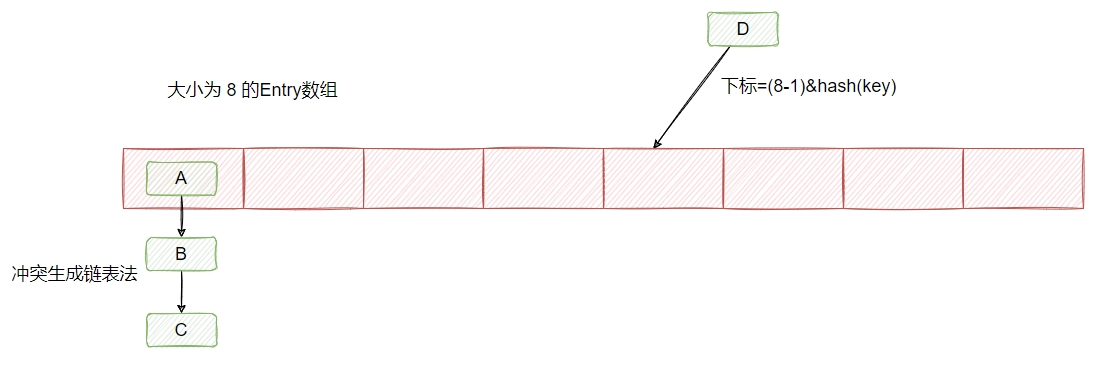
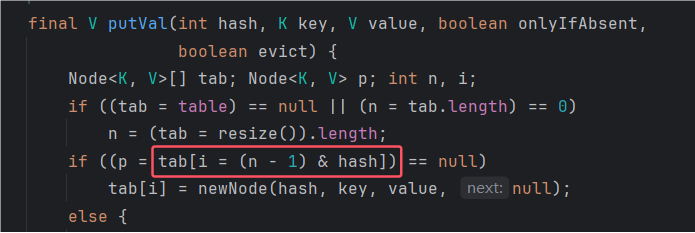
当调用HashMap的put方法新增键值对时,会根据HashMap类的静态方法hash,用键值对的键来计算出哈希值,并用(散列表大小n - 1) & hash的值作为散列表数组下标,将新增的键值对放入。

为解决哈希碰撞,每个散列表数组槽位内是一个链表或红黑树(JDK 8 开始引入红黑树)。当链表长度大于8,且散列表数组长度大于等64时,链表转化为红黑树;当红黑树节点小于6时退化成链表。

来说计算哈希值的hashCode方法。当键不为null时,将键的hashCode方法的值,和自身右移16位的值进行异或,结果作为计算后的哈希值返回。键为空则结果为0。

再来说说(n - 1) & hash这个式子。其实就等同于hash的值对散列表长度n求模:hash % n。这样能确保计算出的哈希值不会超出散列表下标范围。
这里使用与运算&而不是模运算,是因为位运算是直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。
且:
$$ x / 2^n = x >>> n $$
$$ x % 2^n = x & (2^n - 1) $$
当除数是2的n次方时,x除的结果就等于二进制直接右移n位,模的结果就等于x和除数减一的二进制进行与运算。
例:$ 21 / 8 $ 和 $ 21 % 8 $
21的二进制:10101, 8的二进制:01000, 7的二进制:00111
$ 21 / 8 = 21右移三位 = 00010 = 2 $ , $ 21 % 8 = 21 & 7 = 00101 = 5 $
扩容机制
虽然解决了哈希碰撞的问题,但若散列表太小,键值对太多,频繁出现哈希碰撞,链表或红黑树就会变得很长,此时就需要对散列表扩容。
前面提到,键值对放在散列表中的哪个位置,是由(散列表大小n - 1) & hash决定的,与散列表大小有关。现在散列表大小改变了,意味着键值对存放的位置可能发生改变,要计算出扩容后所有键值对的新位置。
JDK1.7 中的做法是每个键值对重新hash映射到新的散列表,在 JDK1.8 进行了改进:
根据之前的结论,散列表长度必须是2n,每次扩容为之前的两倍。这样的好处是,扩容后计算(n - 1) & hash,有变化的只有扩容前的n那一位。
例:原本散列表长度为8,下标为2处有一键值对,现长度扩容为16
8-1的二进制为00111,16-1的二进制为01111
则对于(n - 1) & hash,原先的值就是下标2,即00010,说明hash为??010,扩容后的值应该为0?010。
若?为0,则扩容后位置也不变,无需迁移。若?为1,则扩容后的新位置就是原先的下标加上扩容前的散列表长度。
散列表初始默认容量为16,负载因子为0.75。
头插与尾插
JDK1.8 后 HashMap 由头插法改为了尾插法,为什么?
JDK 1.7 及以前使用头插法,JDK 1.8 及以后使用尾插法。这是因为头插法在HashMap扩容时可能导致环形链表导致死循环。
LinkedHashMap
LinkedHashMap继承自HashMap,所以HashMap有的功能LinkedHashMap全都有。
它是有顺序的。如
若在创建时传入参数accessOrder = true,则每次调用get()或put()时,将访问的节点移动到双向链表尾部(最近访问),适合实现LRU。LinkedHashMap内部的
1 | protected boolean removeEldestEntry(Map.Entry<K,V> eldest) |
方法决定是否要删除最久未被访问的元素。默认当容量满后又有新元素加入则删除最旧元素。
LinkedHashMap遍历内部元素时直接通过双向链表的迭代器进行遍历,而无需像HashMap那样一个个去遍历哈希表(可能有很多空桶),遍历效率更高。
HashMap、ConcurrentHashMap、HashTable 的区别
HashTable使用synchronized来锁住整张表来实现线程安全,即每次锁住整张表让线程独占,相当于所有线程进行读写时都去竞争一把锁,导致效率非常低下。
ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,允许多个修改操作并发进行,其关键在于使用了锁分段技术。使用CAS+synchronized实现更细粒度的锁。当发生哈希冲突时,只锁住冲突的链表或红黑树的头节点。
| 特性 | HashMap | Hashtable | ConcurrentHashMap |
|---|---|---|---|
| 线程安全 | ❌ 不安全 | ✅ 线程安全 | ✅ 线程安全 |
| 锁机制 | 无锁 | 整个方法 synchronized | 分段锁 / CAS |
| 性能 | 高 | 低 | 高 |
| 是否允许 null key | ✅ 允许一个 | ❌ 不允许 | ❌ 不允许 |
| 是否允许 null value | ✅ 允许 | ❌ 不允许 | ❌ 不允许 |
| 出现时间 | JDK1.2 | JDK1.0 | JDK1.5 |
| 推荐使用 | 单线程 | 基本淘汰 | 并发场景 |
HashMap 和 HashTable 的区别
- 父类不同:HashMap继承抽象类
AbstractMap;而Hashtable实现Dictionary类。二者都实现Map接口 - 线程安全不同:Hashtable是线程安全的,而HashMap不是
- 能否有null:Hashtable中key和value都不允许出现null;而HashMap允许有一个为null的key,value可以有多个null,因此不能用
get()返回null来判断HashMap中是否有某个键 - 哈希值的使用不同:Hashtable直接使用对象的
hashCode;而HashMap重新计算哈希值 - 扩容方式不同:HashMap内散列表默认大小为16,扩容后一定为2n;Hashtable初始大小为11,扩容方式为
old * 2 + 1